05 Restaurants and Biking: Predictive Model
Predicting census block bike trips demand in Philadelphia
At this step, we are going to first import Replica dataset and trim it to only look at trip’s Primary mode is Biking. Because the Replica trip only has start and end geoid, so we want to join it with census block data.
from pygris import block_groups
phila_block_groups = block_groups(
state = '42',
county = "101",
year = 2015
)
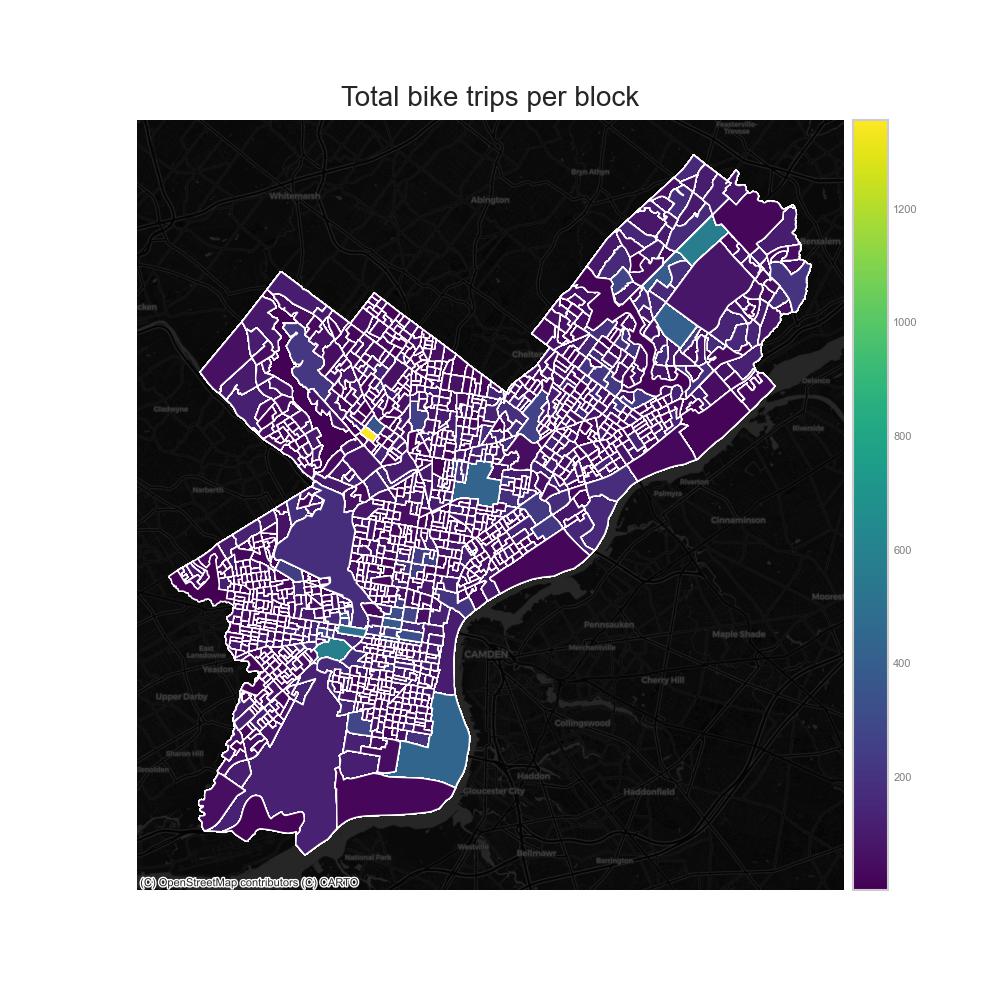
Total bike trips per block
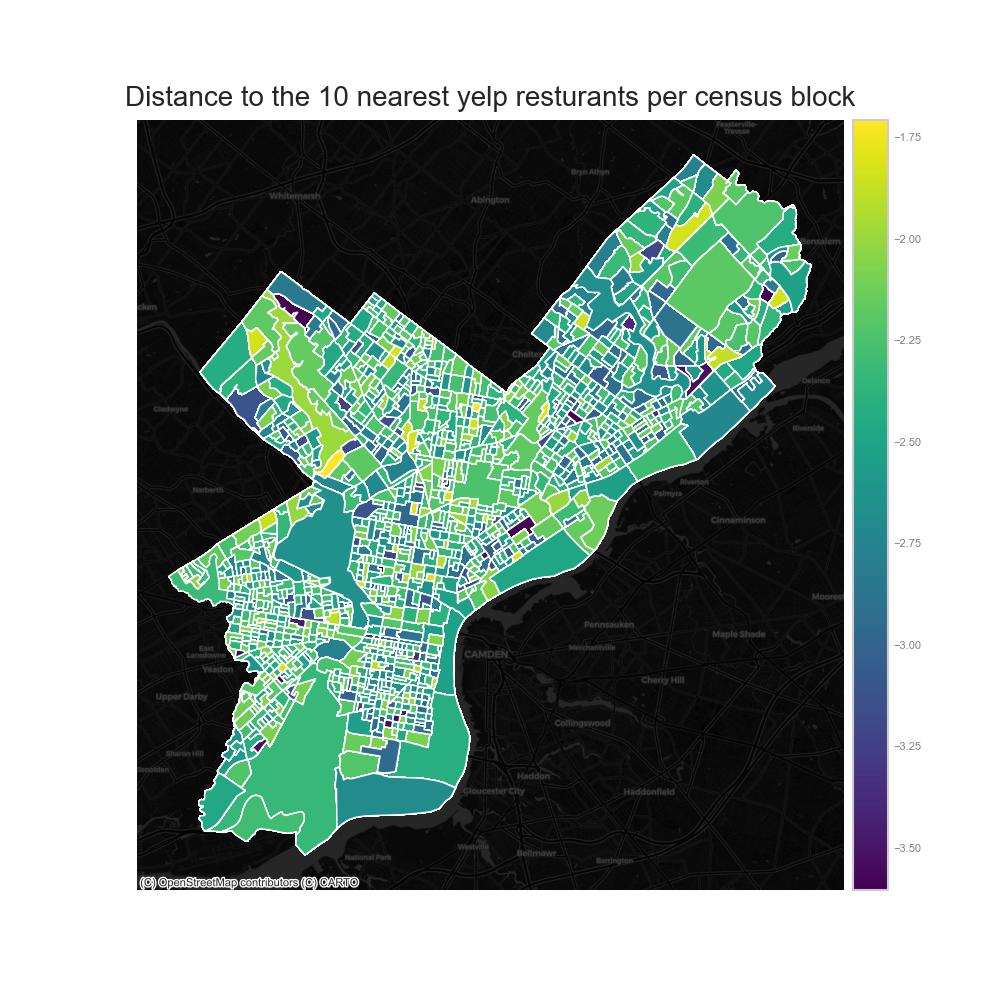
Distance from bike trip start block to 10 nearest Yelp restaurants
Then we want to calcuate the distance from census blocks to the 10 nearest Resturants from Yelp Business and apply log10().
After this step, we also import Indego stations from Indego API, and calculate the nearest Indego station distance
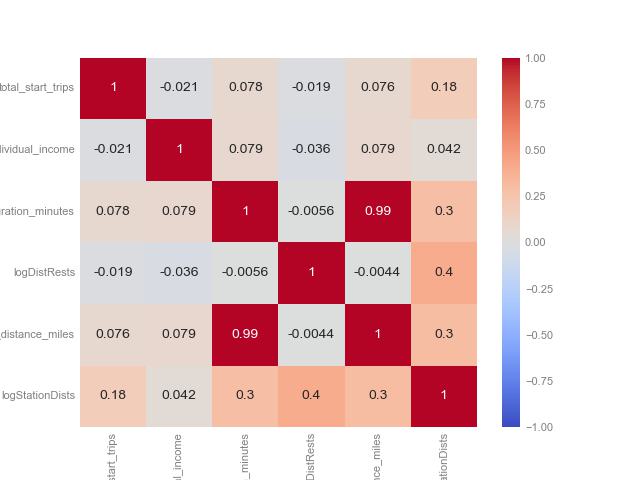
Correlations for all features
All the features like distance to nearest Indego stations, trip duration, distance to Yelp restaurants, income are all not correlated with total trips by census block, the current model’s feautres are not useful enough.
After that we set up pipleline from StandardScaler to RandomForestRegressor, and use GridSearchCV to find out the best params are [‘randomforestregressor__max_depth’: None,’randomforestregressor__9 estimators’: 200].
feature_cols = [
"laggedTrips",
"trip_duration_minutes",
"logDistRests",
"trip_distance_miles",
]
train_set = train_set[feature_cols]
test_set = test_set[feature_cols]
And the grid.score is super low, the prediction is not trust-worthy at all. To think about the total bike trips by each census block, it may related to more about demographic features, or census block level bike trips is not a ideal level to predict bike trip data.